
So You’re Making a Blog.
Let’s say you’re a somewhat recently graduated developer and you find yourself tunnel-visioning on particular technologies at work. If this is the case, in order to not go stale, you’re going to need to find an outlet where you can experiment with new technologies, and record your findings and opinions.
In order to experiment with new technologies you’re going to need to dedicate time and effort to keeping up with the goings on of modern development. This will give you a perfect excuse to feel like you’re not wasting your time and energy on /r/programming and hackernews.
And seeing as you’re going to be conducting experiments and learning about cool new things, you’re also going to need somewhere to host them so that you can share them on the internet. Because of course, if a stranger online doesn’t validate your work, did you do anything at all?
How I made this blog
A note to undergraduates
I’m going to be aiming much of this content at people like you. Specifically, I’m going to be making the kind of content I wish I had access to whilst I was in university. I’ll be aiming to be making complete guides, with links to repositories with the complete code, which actually build, and stays building (perpetual guarantees notwithstanding).
This blog itself could be hosted completely for free. One of the reasons I’ve set this blog up in a more complicated way than it strictly needs to is because I’m testing myself in cloud admin practices and techniques.
If you’d like to host your own blog using Jekyll, or using some other static site builder, go read these docs.
A brief architectural interlude
This blog is, at the time of writing, hosted at jackpenson.dev.
The tech stack currently looks like:
- Jekyll Static Site
- Containerised with nginx
- Proxied with nginx-proxy and docker-letsencrypt-nginx-proxy-companion
- Hosted on Digital Ocean
In the very near future I’m going to add:
- Infrastructure managed via Terraform
- Additional static sites (such as a resume)
Diagrammatically:
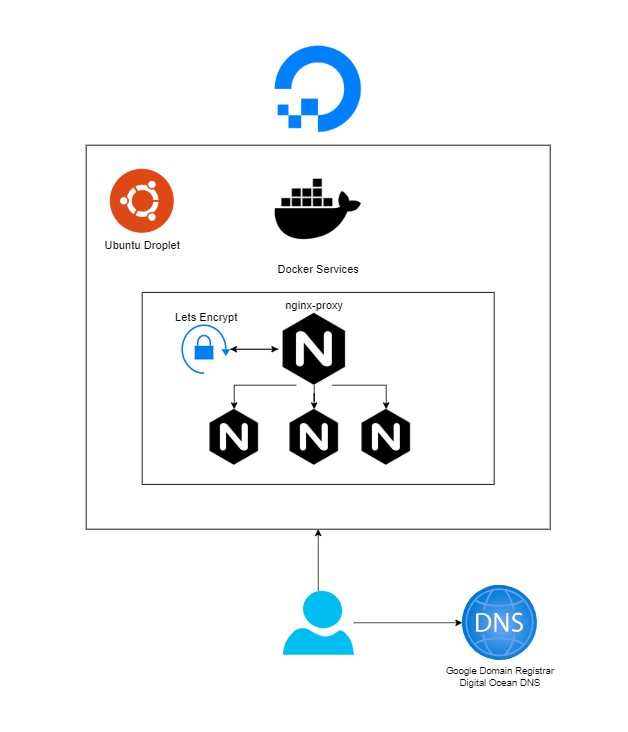
nginx-proxy
Hosting on my own tin (or near enough) gives some distinct advantages over using pre-packaged solutions like GitHub Pages. A key one being that this site isn’t limited hosting just a blog. I plan to host multiple subdomains for the various things I hope to make and blog about.
nginx-proxy is a particularly useful tool for the initial phase of this project. It generates reverse proxy configurations for docker containers running with particular environment variables.
This means that hosting additional sites becomes very straightforward, simply deploy additional containers and inject the correct environment variables, and hey-presto, that’s a new subdomain.
You will of course need to create a new A-Record for that. Which means that for each additional subdomain only two changes are required, adding the container to the list of services (with the right env vars) and updating the DNS config with the new A-Record. Easy peasy.
Let’s Encrypt
There are absolutely no excuses to host a site without https anymore. It’s just bad practice. There is a lot of tooling out there which makes this an entirely brain-dead exercise. docker-letsencrypt-nginx-proxy-companion is designed to be used in tandem with nginx-proxy. Luckily it does JustWork![]() .
.
Refer to the official documentation for how to get nginx-proxy and lets encrypt working together.
Digital Ocean
I’ve opted for digital ocean because it offers a great balance between flexibility and foot-gunning. My day job is a cloud admin focusing on aws, kubernetes, and chef, hosting various internal tooling and self-hosted SaaS services. I don’t need a full Enterprise solution for my personal blog, thank you very much.
However the current digital ocean environment is absolutely a snowflake. The firewall, dns, and droplet are all artisanal hand-made works of art. This will all be redone in terraform so that it can be automatically applied and updated.
Automate ALL the things!
If you haven’t noticed yet, I am a big fan of automation. It allows me to feel like I’m being productive and working on things without actually making anything. In all seriousness however there are some key pieces of automation which I feel is worth talking about.

Continuous Integration
I’m sure I don’t need to convince anyone why this is necessary, but just in case, start here. This blog is hosted on github and new blog entries will be added via PRs.
I’m currently using GitHub Actions as my CI task runner largely because I’ve never used it before. It seems like a very lightweight solution, doesn’t require additional accounts, and JustWorks![]() for my needs. I do plan on doing some kind of comparative analysis of the CI platforms with free tiers, some are certainly better than others at certain things.
for my needs. I do plan on doing some kind of comparative analysis of the CI platforms with free tiers, some are certainly better than others at certain things.
Continuous Deployment
At this current moment the website is not being continuously deployed. This saddens me greatly but is definitely going to be the next thing I work on.
As this is just a bunch of docker containers, the plan is to create a new repository for all terraform with a docker-compose file for deploying them. I reckon it can be as simple as having a github action on any of the subdomain sites which uses ssh -t to restart the images with the latest tags on the droplet.
What I’m doing right now is using two hacky scripts:
docker run --detach \
--name nginx-proxy \
--publish 80:80 \
--publish 443:443 \
--volume /etc/nginx/certs \
--volume /etc/nginx/vhost.d \
--volume /usr/share/nginx/html \
--volume /var/run/docker.sock:/tmp/docker.sock:ro \
jwilder/nginx-proxy
docker run --detach \
--name letsencrypt \
--volumes-from nginx-proxy \
--volume /var/run/docker.sock:/var/run/docker.sock:ro \
--env "DEFAULT_EMAIL=encrypt@jackpenson.dev" \
jrcs/letsencrypt-nginx-proxy-companion
docker run --detach \
--name blog \
--env "VIRTUAL_HOST=jackpenson.dev" \
--env "VIRTUAL_PORT=8080" \
--env "LETSENCRYPT_HOST=jackpenson.dev" \
ghcr.io/penson122/personal-blog
docker kill $(docker ps -a -q)
docker rm $(docker ps -a -q)
And on the box:
$ ./kill.sh && ./start.sh
So what I’ll end up with is a docker-compose definition of all the containers and their config and a restart script. Then all I’ll need to do is
$ ssh -t me@digital-ocean "restart.sh"
Of course this doesn’t guarantee zero-downtime releases and would not be suited to high availability environments. But it doesn’t need to be. If I ever get to the point where high availability is a concern I doubt I’ll be running all the subdomains from a single $5 droplet.
Principles and Praxis
It may seem strange that so much of my initial focus on this first post is around CI/CD principles and practices. I am firmly in the camp that the very first thing you should do when working on a project is to get it into production. The easiest way to get code into production in a repeatable and safe manner is via CI pipelines.
Before even working on this first blog post I had the demo site that came with jekyll deployed to the public internet under a test sub-domain. Originally this site was deployed at blog.jackpenson.dev.
When undergoing any new project it’s important to create measurable outcomes and plans to achieve those outcomes. As you break down the units of work involved you’ll quickly discover that some work presents particular risks or knowledge gaps.
This can be succinctly represented via Johari Windows with a little editing from their original purpose.
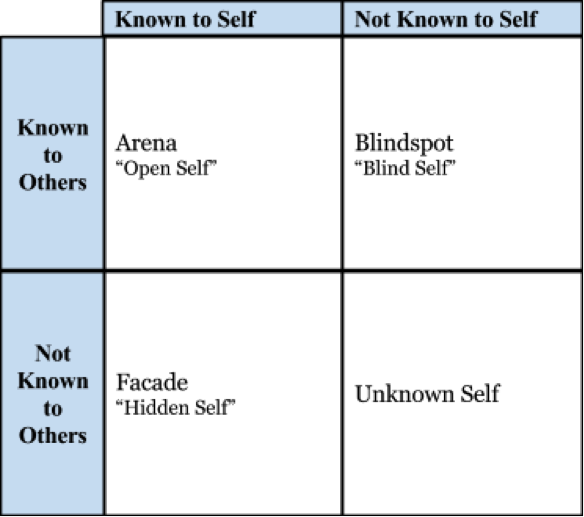
This technique is useful to breakdown what work presents the most risk. Those in the top left corner should be the bread and butter work, the bottom right is the risky endeavour. Here the understanding of a particular problem domain or design challenge is what creates the risk.
In technical projects rather than their original purpose of psychological analysis each category takes on a slightly shifted meaning. This interpretation of the Johari Window aligns much closely to that of the Design Thinking model.
Known Knowns
The category of work that is immediately solvable and understood. There are ample resources to achieve this task, and those performing the task know to perform it.
In the development of this blog, the usage of static site builders and markdown driven content is a known-known for me. So is containerisation for deployment of software.
- Known to both self, and to others.
Known Unknowns
Typically this would cover new skills, techniques or the first implementations of some theory. There is a definite prior art but no experience for those performing the task.
This would be the usage of docker-gen and nginx-proxy. I had no personal experience deploying a static site in this manner, but it was clear that others had success doing it this way and there was prior art for how to do so.
- Not known to self, but is to others.
Unknown Knowns
Some internal experience that is unique to those performing the task. Organizationally, this might be some unique selling point internally developed.
Personally, this would be my sum total of experience that I hope to express via blog posts.
- Known to self, but not to others
Unknown Unknowns
The truly risky categories of endeavours. Typically it’s safer to play in the known unknown/unknown known categories of explorative work. This typically occurs when you cut yourself playing at the razors edge of innovation. This may happen when stacking particular technologies on top of each other in unexpected ways. This is also the genesis of scientific discovery, when petri dishes turn into penicillin this is unknown unknowns in action.
- Not known to self, or to others.
Leveraging unknowns
There are various categories of work which inevitably lead to discovery and exploration but unfortunately the only way to avoid hitting those categories is to stay in the “known knowns” quadrant and never innovate or learn. Given this, it’s critical to challenge those unknowns directly. They represent the greatest amount of risk to a project and should be best understood before proceeding with any other aspect of it. Or rue the day when you need to re-architecture your entire stack because your assumptions bite you very late in the game.
However these challenges always present a high degree of churn, you’ll quickly hit walls in your understanding and it’s typically best to scrap the work and retry. This is the failing fast model of development. Typically pairs best with some hypothesis based on your outcomes.
Outcome:
- I want to start a website, with a blog, and subdomains for other projects.
Hypothesis:
- Docker is a suitable mechanism for deploying and organising multiple sites.
This immediately places the known parts of the known unknowns to the forefront of the task providing a framework with which to tackle the problem. In this case, I should:
- Research images used to host static sites
- apache, nginx, etc.
- Research how to host multiple sites
- Load balance multiple instances, all from a single machine, etc
- Test and implement various discoveries from this research
I’m telling a bit of a lie here, because I already had a good idea that using a single instance with a reverse proxy would be the cheapest and simplest option for starting out. But I did have to research ways of deploying reverse proxies using docker, and the costs of using serverless deployments behind a load balancer. In the end, the solution with the least headache, and the most opportunity for learning was to use the nginx-proxy container and a single static host. So once I had tested on a hastily constructed droplet that I could use nginx-proxy to automatically create subdomains and that they were reachable I was happy with my experimentation phase and quickly put together a pipeline.
The first thing that I did once I had a plan that was actionable was to create a test environment and prove out my assumptions. Luckily they were correct and it was fairly smooth sailing. If it had been the case that for example, nginx-proxy was poorly maintained and it didn’t work appropriately, or that I had made assumptions about how various parts of the stack fit together such as nginx not being suitable for hosting jekyll sites then at this point I would have scrapped the stack and gone a different route. Likely I would have looked at using Google Cloud Functions, or AWS Lambdas.
If you look at the pull request history, you’ll see that the first two were to add the demo site that comes with jekyll new, a dockerfile and a workflow to publish the container. This made it trivial test ways of deploying the site. All I had to was pull and run the container on a host with docker installed.
Having this single artefact with which to deploy the site meant that I could quickly innovate and prove out my unknowns, those being using a reverse proxy with multiple subdomains, and using docker to host the targets for those subdomains.
Even though the site was initially broken, it suited the purpose of a “hello, world!” app. It was also simple to fixup and update in production.
The alternatives could have been locally bundling the site, pushing it to the sever, and rebuilding the container. Instead it was git push, docker pull, ./kill.sh && start.sh. An obviously much simpler, repeatable, process which less room for error, and frustration. With the ability to roll back to boot.
To summarise: when starting new projects first interrogate any gaps in understanding, then experiment to prove assumptions, and leverage automation to simplify process and accelerate experimentation.
Endings are weird
I plan on writing more about CI/CD practices, DevOps, maybe even something around art and programming. Particularly I’d like to play around with parsing or constructing conceptual art pieces like those of Laurence Weiner. Maybe even some generative art?
So yeah thanks for reading the first of I hope, at the very least, several posts.